KcBERT 와 파인튜닝으로 멀티라벨 악플 분류 모델 만들기


지난 포스트에 이어서 "한국어 혐오표현 데이터셋" 을 가지고, 문장이 어떤 종류의 혐오를 담고 있는지 BERT 모델 기반으로 파인튜닝하고 최적화 하는 과정을 학습차원에서 정리 해보고자 한다.
 smilegate-ai
smilegate-ai1. 모델에 대하여
1) BERT
BERT 는 트랜스포머라는 신경망을 사용하고 대량의 텍스트데이터로 사전훈련을 한 모델이다. BERT는 다양한 자연어 처리 작업에서 높은 성능을 보여주고 있다.
사전 훈련을 할때는 두가지 방법을 사용하는데,
첫번째로 Masked Language Modeling 이라고 문장에서 임의의 단어를 가리고 그 단어를 맞추는 과정이다. 이렇게 하면 모델은 문장의 전체적인 의미와 문맥을 파악할 수 있다.
두번째로 Next Sentence Prediction 이라고 두개의 문장이 주어졌을때, 두번째 문장이 첫번째 문장의 다음에 오는 문장인지 아닌지를 판단하는 과정이다. 이렇게 하면 모델은 문장 간의 관계와 논리를 이해할 수 있다.
이렇게 사전훈련 된 BERT 는 다른 자연어 처리 작업에 적용하기 위해 추가적인 파인튜닝 과정에서 얻은 지식을 결합하여 높은 성능을 낼 수 있다.
2) KcBERT
KcBERT 는 한국어 문장 처리를 위해 사전 훈련된 언어 모델로, "온라인 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 BERT모델을 처음부터 학습한 Pretrained BERT 모델" 이라고 소개하고 있다.

2. KcBERT 파인튜닝 하기
1) Custom DataSet 구성
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer, AutoModelForSequenceClassification, AdamW
class CustomDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_length):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, index):
text = self.texts[index]
label = self.labels[index]
encoding = self.tokenizer(text, padding='max_length', truncation=True, max_length=self.max_length, return_tensors='pt')
input_ids = encoding['input_ids'].squeeze()
attention_mask = encoding['attention_mask'].squeeze()
return {'input_ids': input_ids, 'attention_mask': attention_mask, 'label': label}def check_label(label):
if label['여성/가족'] == 1:
return 0
elif label['남성'] == 1:
return 1
elif label['성소수자'] == 1:
return 2
elif label['인종/국적'] == 1:
return 3
elif label['연령'] == 1:
return 4
elif label['지역'] == 1:
return 5
elif label['종교'] == 1:
return 6
elif label['기타 혐오'] == 1:
return 7
elif label['악플/욕설'] == 1:
return 8
elif label['개인지칭'] == 1:
return 9
else:
return 10
# 혐오 표현 데이터셋
rawdata = pd.read_csv('unsmile_train_v1.0.tsv', sep='\t')
texts = []
labels = []
for idx, label in rawdata.iterrows():
texts.append(label['문장'])
labels.append(check_label(label))
# KcBERT 모델과 토크나이저 로드
model_name = "beomi/kcbert-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=11)
# 원하는 최대 시퀀스 길이
max_length = 128
labels = torch.tensor(labels, dtype=torch.long)
dataset = CustomDataset(texts, labels, tokenizer, max_length)
# 데이터 로더 생성
batch_size = 11
# Train / Test set 분리
from sklearn.model_selection import train_test_split
train, test = train_test_split(dataset, test_size=0.15, random_state=42)
train_dataloader = DataLoader(train, batch_size=batch_size, shuffle=True)
valid_dataloader = DataLoader(test, batch_size=batch_size, shuffle=True)2) 모델 재학습과 평가
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 하이퍼파라미터 설정
learning_rate = 1e-5
epochs = 5
# 옵티마이저 및 손실 함수 설정
optimizer = AdamW(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
# 모델 재학습
for epoch in range(epochs):
model.train()
total_loss = 0
for batch in train_dataloader:
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['label']
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
# 그래디언트 초기화
optimizer.zero_grad()
# 모델에 입력을 주어 예측을 생성합니다.
outputs = model(input_ids, attention_mask=attention_mask)
# 모델 출력에서 로짓(분류에 대한 점수)을 얻습니다.
logits = outputs.logits
# 손실을 계산합니다.
loss = criterion(logits, labels)
# 역전파를 통해 그래디언트 계산
loss.backward()
# 옵티마이저를 사용해 가중치를 업데이트
optimizer.step()
# 에포크 전체 손실을 누적합니다.
total_loss += loss.item()
# 에포크 평균 손실 계산
avg_loss = total_loss / len(train_dataloader)
# 에포크별 손실 출력
print(f"Epoch {epoch+1}/{epochs} - Avg Loss: {avg_loss:.4f}")
# 모델 평가
model.eval()
val_total_loss = 0
correct = 0
total = 0
with torch.no_grad():
for val_batch in valid_dataloader:
# Validation 데이터 가져오기
val_input_ids = val_batch['input_ids']
val_attention_mask = val_batch['attention_mask']
val_labels = val_batch['label']
val_input_ids = val_input_ids.to(device)
val_attention_mask = val_attention_mask.to(device)
val_labels = val_labels.to(device)
# 모델 예측
val_outputs = model(val_input_ids, attention_mask=val_attention_mask)
val_logits = val_outputs.logits
# 손실 계산
val_loss = criterion(val_logits, val_labels)
val_total_loss += val_loss.item()
# 정확도 계산
val_preds = val_logits.argmax(dim=1)
correct += (val_preds == val_labels).sum().item()
total += val_labels.size(0)
val_avg_loss = val_total_loss / len(valid_dataloader)
val_accuracy = correct / total
print(f"Validation Loss: {val_avg_loss:.4f} - Validation Accuracy: {val_accuracy:.4f}")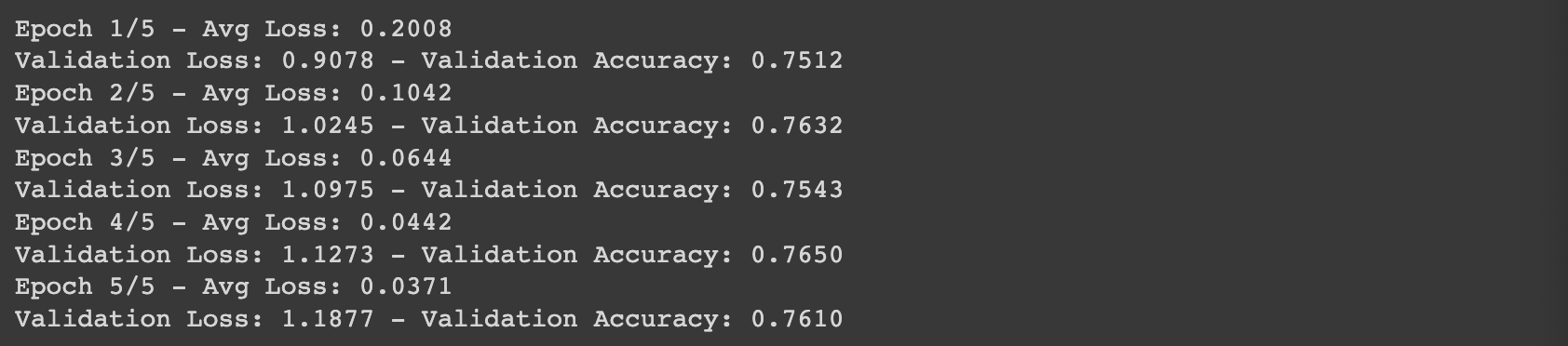
데이터셋 크기 문제인지, 정확도가 76% 로 다소 떨어진다. 추후에 데이터를 늘려서 테스트 해볼까 싶다.
3) 모델 저장 및 로드
# 모델 저장
model_save_path = "kc_bert_emotion_classifier.pth"
torch.save(model.state_dict(), model_save_path)
# 모델 아키텍처 생성
loaded_model = AutoModelForSequenceClassification.from_pretrained("beomi/kcbert-base", num_labels=11)
# 저장된 가중치 불러오기
loaded_model.load_state_dict(torch.load(model_save_path))
# 모델을 평가 모드로 설정
loaded_model.eval() 4) 모델 테스트 하기
def valid_label(label):
if label == 0:
return '여성/가족'
elif label == 1:
return '남성'
elif label == 2:
return '성소수자'
elif label == 3:
return '인종/국적'
elif label == 4:
return '연령'
elif label == 5:
return '지역'
elif label == 6:
return '종교'
elif label == 7:
return '기타 혐오'
elif label == 8:
return '악플/욕설'
elif label == 9:
return '개인지칭'
else:
return '일반문장'
# 입력 데이터 준비 (위 예제와 유사한 방법으로)
input_data = [
"한남 씹선비들 지랄하네",
"동성애는 정신병이다 이기야",
"김치년들 지랄하노",
"안녕하세요 씹새끼여러분",
"반갑습니다. 좋은 하루 시작하세요",
"홍어새끼들 또 지랄이노",
"먹사새끼들 신났네",
"떡검새끼들 신났네",
]
input_encodings = tokenizer(input_data, padding=True, truncation=True, return_tensors="pt")
# 모델에 입력 데이터 전달
with torch.no_grad():
output = loaded_model(**input_encodings)
# 예측 결과 확인
logits = output.logits
predicted_labels = logits.argmax(dim=1)
# 예측 결과 출력
for i, input_text in enumerate(input_data):
predicted_label = predicted_labels[i].item()
print(f"Input: {input_text} - Predicted Label: {valid_label(predicted_label)}")

결과는 비교적 정확하게 올바른 혐오표현의 라벨을 예측한 것으로 나온다. 어떻게 하면 정확도를 더 높일 수 있을까 ?